pd
2022-04-05 09:47:07 UTC
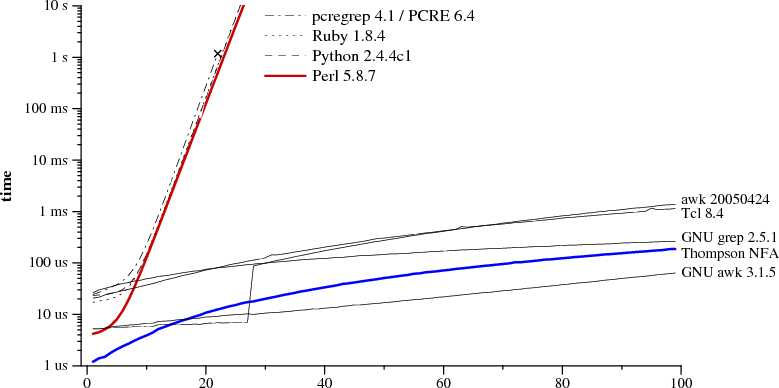
I was reading an article [1] about algorithms implementing regular expressions when I saw this picture [2], tcl regex performance is six orders of magnitude faster than perl regex for certain regular expression, I was really shocked and couldn't believe it, so I've checked, and that's true, tcl regex works in microseconds where perl regex consume seconds:
% set s [string repeat a 30]
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% set r "[string repeat a? 30][string repeat a 30]"
a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% time {regex $r $s m}
199 microseconds per iteration
now 1649120014 s
ok
exec time: 53.366160 s
now 1649120014 s
dif 0 s
Presione una tecla para continuar . . .
$ time ./p.pl
ok
real 0m 52.30s
user 0m 52.12s
sys 0m 0.01s
with p.l :
#!/bin/perl
$s = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa";
if ( $s =~ /a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/ ){
print "ok\n";
}
I really cannot believe perl regex which is the de facto standard performs so badly, the same applies to pcre lib and so most scripting languages like python, ruby... It's true this is only in certain cases which may be not so common but the article gives examples of common regex affected.
Another point to tcl bag ;-)
[1] https://swtch.com/~rsc/regexp/regexp1.html
[2] Loading Image...
% set s [string repeat a 30]
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% set r "[string repeat a? 30][string repeat a 30]"
a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% time {regex $r $s m}
199 microseconds per iteration
now 1649120014 s
ok
exec time: 53.366160 s
now 1649120014 s
dif 0 s
Presione una tecla para continuar . . .
$ time ./p.pl
ok
real 0m 52.30s
user 0m 52.12s
sys 0m 0.01s
with p.l :
#!/bin/perl
$s = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa";
if ( $s =~ /a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/ ){
print "ok\n";
}
I really cannot believe perl regex which is the de facto standard performs so badly, the same applies to pcre lib and so most scripting languages like python, ruby... It's true this is only in certain cases which may be not so common but the article gives examples of common regex affected.
Another point to tcl bag ;-)
[1] https://swtch.com/~rsc/regexp/regexp1.html
[2] Loading Image...